System Design Interview – An insider's guide を読んだ
これ

以下のChapterは著者のサイト https://bytebytego.com/ で同じものがフリーで読める。
- Chapter 1: Scale From Zero To Millions Of Users
- Chapter 2: Back-of-the-envelope Estimation
- Chapter 3: A Framework For System Design Interviews
- Chapter 12: Design A Chat System
- Chapter 14: Design Youtube
本の概要
有名なThe System Design Primerと似ている。
The System Design Primer: https://github.com/donnemartin/system-design-primer (※日本語翻訳版も同じリポジトリにある)
System Design Interview はタイトルの通り、技術面接寄りの観点とか、面接官とのコミュニケーション(質問とか深堀りとか)が入ってる量が多く感じた。
目次
amazonから引用
Chapter 1: Scale From Zero To Millions Of Users Chapter 2: Back-of-the-envelope Estimation Chapter 3: A Framework For System Design Interviews Chapter 4: Design A Rate Limiter Chapter 5: Design Consistent Hashing Chapter 6: Design A Key-value Store Chapter 7: Design A Unique Id Generator In Distributed Systems Chapter 8: Design A Url Shortener Chapter 9: Design A Web Crawler Chapter 10: Design A Notification System Chapter 11: Design A News Feed System Chapter 12: Design A Chat System Chapter 13: Design A Search Autocomplete System Chapter 14: Design Youtube Chapter 15: Design Google Drive Chapter 16: The Learning Continues
Chapter1〜3: システム設計の基礎
Chapter 1: Scale From Zero To Millions Of Users
徐々にサーバーを増やしていったり、キャッシュを挟んだり、Queueを挟んだりしていく、「よくやるやつだね」という印象。
ただ一連の流れとしてまとまっているのを他であまり見たことがないので、経験の少ない人におすすめしたり、一緒に読んだりする時にとても良さそう。
Chapter 2: Back-of-the-envelope Estimation
レイテンシー、SLAとダウンタイム、QPSやストレージの概算見積もりなど。
これもこのあとの議論のための基礎固めな印象。
Chapter 3: A Framework For System Design Interviews
インタビューを以下の4ステップで行うことを勧めている。
- Step 1 - Understand the problem and establish design scope
- 問題の把握と、デザインスコープを設定する
- Step 2 - Propose high-level design and get buy-in
- ハイレベルな(全体的な概要レベルの)設計をして、同意を得る
- Step 3 - Design deep dive
- Step 4 - Wrap up
- 仕上げに振り返りをしたり、自由に議論をしたりする
実際にChapter4以降は、それぞれのChapterがこの4ステップの Subchapterで構成されている。
このステップは面接だけでなく、仕事で本当にシステム設計の議論やレビューをする際にも同じようにやってるなーと感じた。
なので、設計ドキュメントの章立てに取り入れるとか、レビュー会のアジェンダにも取り入れるとか、設計観点のエンジニア育成なんかにも良さそうに思った。
Chapter4〜7: プロダクトの設計ではなく、個別機能の設計ぽい感じ
- Chapter 4: Design A Rate Limiter
- Chapter 5: Design Consistent Hashing
- Chapter 6: Design A Key-value Store
- Chapter 7: Design A Unique Id Generator In Distributed Systems
この辺は実務だとライブラリとかクラウドサービスにおまかせしちゃうことが多い領域だと思う。
中身のアルゴリズムとか仕組みが分かると、どれにするか選ぶか考えるときにより深く考えられたり、設定項目の意図とか影響もよく分かるようになるので、知識としてたくさんストックしておくのが大事だなーと思う。(これはデータ指向アプリケーションデザインを読んだときにも思った)
Chapter 8〜15: プロダクトの設計
- Chapter 8: Design A Url Shortener
- Chapter 9: Design A Web Crawler
- Chapter 10: Design A Notification System
- Chapter 11: Design A News Feed System
- Chapter 12: Design A Chat System
- Chapter 13: Design A Search Autocomplete System
- Chapter 14: Design Youtube
- Chapter 15: Design Google Drive
いろんなシステムがあって、その裏にはいろんな工夫があるんだなー、とワクワクした。
特に News Feed System、Chat System、Autocomplete System あたりは、これまでの自分の開発経験の延長線上には無い感じがあって、とても面白かった。
(メインのChapterだけど、細かく書くと本の要約みたいになっちゃうので、気になる方はぜひ読んでください)
Chapter 16
- Chapter 16: The Learning Continues
Facebook, Netflix, Googleなどの公開資料へのリンクがたくさん載っている。
(ちなみにhapter16に限らず、各Chapterにも参考リンクがたくさん載っていて、深堀りできるリソース紹介は全体的にかなり多い)
次に読むおすすめ本の紹介では下記2冊がおすすめされていて、分散システムを学ぶことが大事というメッセージを感じた(もう1冊おすすめされていたのはレジュメの本)

↑ 書籍で紹介されていたのは第一版だけど、2nd editionが出ていた

↑ 書籍で紹介されていたのは英語版
その他の感想
タイトルから、どのようなコンポーネント構成にするか(サーバーを分けたり、キャッシュや非同期の機構を入れたり)がメインだと思っていた。
実際に読んでみるともちろんそういう内容が多いけれど、アルゴリズムとかデータ構造とかの細かい話も多く出てきた。
かつ、それらが実システムでどこにどう役立つかとセットで説明されているので、単発で紹介されるよりも頭に入ってきやすいと思った。
具体的にはこういうのが出てきた
- Rate Limitのアルゴリズム
- Consistent hashing(コンシステントハッシュ法)
- Vector Clock
- Merkle tree(ハッシュ木、マークル木)
- Bloom filter(ブルームフィルタ)
- trie(トライ、tree-like data structure)
まとめ
とてもおすすめ
Volume 2も出ているのでそのうち読みたい(現時点で無いみたいだけど、電子版が出てほしい)

A Philosophy of Software Design を読んだ
A Philosophy of Software Design を読みました
")
全体の感想
賛否あるだろうなという内容もちらほらあったと思うが、自分はほとんどの章について同意だった。
小さなクラスに分けまくるのを推奨していない印象で、あくまでインタフェースが重要で、クラス設計やメソッド設計・コマンド実行時のオプション設計など、いずれの場合も、利用者から情報を適切に隠蔽すること・シンプルに明白にすること、という方針が良いと思った。
特に心に残ったところ
3 Working Code isn't Enough
- 動くコードだけでは十分ではない
- Tactical Programming (戦術的プログラミング)
- できるだけ早く機能を動作させることに焦点を当てた考え方
- Strategic Programming (戦略的プログラミング)
- 今の仕事を早く終わらせるために不必要に複雑なものを導入してはいけない
- 戦術的トルネード(a tactical tornado)
- 他の人より遥かに早くコードを書くが、戦術的な方法で仕事をするため、破壊の軌跡を残す
- 戦術的トルネードが残した混乱を一掃する本当のヒーローであるエンジニアは、戦術的トルネードよりも進捗が遅く見える
- 最適なアプローチは、継続的にたくさんの小さな投資をすること
- 全開発時間の10〜20%程度を投資に費やすことがお勧め
新規ではなく機能追加の際、特に小さい変更だと戦術的プログラミングで妥協することが実際ちょくちょくある。問題が大きくなってきてからリファクタリングするのは大変で、後できれいにしきれないことも実際良くある。 普段から小さい投資を行い、それをコントロールできる知識や余裕を持つ必要があるなと再認識した。
4 Modules Should Be Deep
- Deep Modules
- 強力な機能を提供しながらも、シンプルなインターフェースを持つ
- Shallow Module
- 提供する機能に対してインターフェイスが複雑なもの
- クラスや他のモジュールを設計する際の最も重要な問題は、それらを深くすること
- 一般的なユースケースのためのシンプルなインターフェースを持ち、なおかつ重要な機能を提供すること
- これによって、クラスや他のモジュールに隠蔽される複雑な部分を最大化することができる
Deep / Shallow という言い分けがとてもいいなと思った。
実際の例がこのあとも繰り返し出てくるので、イメージを持ちやすい。 (が、本を読んでいない人にうまく説明できる自信はないので、ぜひ読んでほしい)
19 Software Trends
- Agile development
特にアジャイルのほうで、小さくリリースできる単位でサイクルを回していくのが正義 みたいな書籍・記事が多い印象で、ちょっと違和感があったのだが、なんとなく言語化されて腑に落ちた。 うまくやらないと戦術的プログラミングに寄りすぎるんだなと思った。
まとめ
設計スキルを上げたいと言われると、これはでは色んなパターンを知ってみたら?という返し(つかってるFWの機能をもっと知る・他の人の書いた機能を読んでみる・OSSを読んでみる)になっていて、うまく答えられてる自信がなかったのだが、今後は自信を持ってこの本をおすすめしていきたい。
コードレビュー時の心構え
社内の勉強会で「コードレビューのコツ」というタイトルで、3人で分担して発表しました。 3人が被らないよう、自分は抽象度高めで心構えについて話しました。
当日入っていた実コードのスクショは入れられないのでだいぶ分かりにくい気がしますが、せっかくなので残しておきます。
レビュー時の心構え 1
大から小へ
- 細かい指摘で満足しないように気をつける
- 無意識にdiffを見ると、細かい指摘をたくさんして満足しかねない
- 大枠から把握していく
- レビューの目的は何か理解する
- どの段階でのレビュー依頼か把握する
- 仮実装なのか、正常系は完了なのか、テスト等も完了なのか
- どの段階でのレビュー依頼か把握する
- 変更の目的を把握する
- 要件定義書や基本設計書を読む
- 暫定対応や納期優先なのか、将来を見越して結構変えているのか
- 規模感や、肝がどこか把握する
- Pull Request の Files changed をざっと下まで見る
- 触っているファイル数や、影響範囲を把握する
- diff ごとに、ざっくりリファクタの部分と機能(仕様)変更の部分を把握する
- 肝となるところを確認する
- ここまで来て初めて、上から丁寧に見る
- 必要ならgit pullして慣れているIDEで見る・動かしてみる
- 呼び出し元ジャンプしたり検索しながら見る
- レビューの目的は何か理解する
レビュー時の心構え 2
具体的にイメージする
- リリースをイメージする
- 単体でリリースするのか、他とセットなのか
- リリース時のアクセスどうなる?
- カラム追加、既存データのデフォルト、など
- 「 migration流れた」〜「コードのリリースが 終わる間」のアクセスもエラーは出ない?
- ALTER TABLE の時間どのくらいかかる?
- テーブルロックされない?
- 「ユーザーが画面を開いた」 →「リリースされた」→「ユーザーが登録ボタンを押した」ってなっても大丈夫?
- カラム追加、既存データのデフォルト、など
- 運用をイメージする
レビュー時の心構え 3
未来を考える
- 対象データやDBのレコードは、どのくらいのスピードで増えるか
- データ量や処理速度は何かに比例する?
- O(n*2) になってない?
- n年後には何レコードくらいになる?
- その Select、データが増えても1回で大丈夫?メモリに載る?
- データ量や処理速度は何かに比例する?
- 後で読んで分かるか
- 読んでも分からない意図や背景がないか
- コメントに残っているか
- Pull Requestも、後で見られても分かるようにする
- 直接話したこともメモを残す
- 「口頭で話したとおり○○○が良いと思います」
- 「○○○ですが、○○○と話したので今回はこのままとします」
- Slackのリンクを貼っておくのも良い
- 読んでも分からない意図や背景がないか
その他のコツ
先回りする・具体的に・効率的に
- 依頼時は、概要や関連資料、見てほしい観点等を伝える
- 絶対聞かれるだろうなと思うところは先にコメントしておく
- Pull Request 作ったら、自分で diff にコメントしても良い
- 絶対聞かれるだろうなと思うところは先にコメントしておく
- レビューがおわったら
- 何を見たか・見ていないか伝える
- 「○○までレビューしました。○○の部分を直したら再レビューします」
- 「このへんは自信がないから◯◯さんにも見てもらってください」
- 何を見たか・見ていないか伝える
- 具体で話す
- コードで伝える
- 「○○のほうが○○になるのでいいと思います。<具体的なコード...>」
- 「○○メソッドを使うと簡潔に書けます。<具体的なコード...>] 」
- 根拠を載せる・URLを載せる
- 図で伝える
- 簡単な手書きの図でも、あるとぜんぜん違うこともある
- コードで伝える
- 必要なら対面で話す
- 指摘が多いとき
- 伝わりにくそうだと思ったとき
- 議論したいとき
質の高い議論のために
勉強する
- 言語やフレームワーク、ライブラリの機能
- Ruby on Rails なら
- とくにActiveRecord、RailsガイドはActiveRecordのボリュームが多い
- 裏で実行されている SQL
- データベースの機能
- とくにActiveRecord、RailsガイドはActiveRecordのボリュームが多い
- Ruby on Rails なら
- インフラ構成
- 計算量とアルゴリズム
- 速度感覚を持つ
- メモリに乗せる > 優先ネットワーク(≒データセンター内) ≧ ディスクアクセス > サーバーをまたぐ >>> インターネット越し(外部サービス)
Electronでメニューバー常駐アプリを作ったメモ
作ったもの
macOSのメニューバーに常駐し、BGMを流せるだけのアプリ
- 起動するとメニューバーに常駐
- start BGM で音楽開始
- stop BGM で音楽停止
- Quit でアプリ終了
https://github.com/miukoba/quick-bgm
必要な知識
まず公式の Quick Start Guide をやった、10分くらい
- https://www.electronjs.org/docs/tutorial/quick-start
- 後半で Electron Forge で簡単に配布できるアプリ形式を作れることが分かった
メニューバー常駐アプリはこの記事を参考に読んだ
開発内容
https://www.electronforge.io/ の方法でプロジェクトを作成
npx create-electron-app quick-bgm cd quick-bgm npm start
index.js, index.html をいじって npm start で確認の繰り返し
今回 index.js, index.html 以外は、アプリ用のアイコン作ったり、mp3や画像ファイルを置いたりしただけ
最後に実施するアプリのパッケージ作成は下記コマンド
npm run make
つまったところ
画面無しのアプリなので BrowserWindow を作成せず、メインプロセス( index.js )で直接音を鳴らそうとしたが、うまく行かず、下記を見つけた
node.js - Playing Audio in Electron from main process - Stack Overflow
一旦これで音を鳴らすことができた
- 見えない
BrowserWindowを作成width: 0, height: 0
- javascript で HTML5 の
HTMLAudioElementを作成new Audio('path/to/file')
- ICP 通信でAudioの再生・停止を制御
mainWindow.webContents.send,ipcRenderer.on('play-bgm', (event, args)- ICP通信はこの記事を参考にした Electron IPC通信を行う方法まとめ │ Web備忘録
- これも簡単にするため
nodeIntegration: trueを指定して、index.htmlでrequire('electron')してしまっているが、セキュリティ的にあまり良くないのでやめたほうがいいらしい
音楽を再生する他の方法を調べると、Electronの音楽プレイヤーアプリ等で WebAudio API を使用しているコードもあった。ただ結構複雑そうだったため一旦は簡単な方法で妥協した
簡単な方法や分わかりやすい解説があれば知りたいです
メインのコード
index.js
const {app, BrowserWindow, Tray, Menu, MenuItem} = require('electron') const ICON_PATH_PLAYING = `${__dirname}/img/icon_playing.png` const ICON_PATH_STOPPING = `${__dirname}/img/icon_stopping.png` let mainWindow let tray app.on('ready', () => { tray = new Tray(ICON_PATH_STOPPING) const menu = new Menu() menu.append(new MenuItem({ label: 'start BGM', click: () => { startMusic() }, })) menu.append(new MenuItem({ label: 'stop BGM', click: () => { stopMusic() }, })) menu.append(new MenuItem({type: 'separator'})) menu.append(new MenuItem({role: 'quit'})) tray.setContextMenu(menu) createWindow() }) app.on('ready', () => { app.dock.hide() }) const createWindow = () => { mainWindow = new BrowserWindow({ // width: 100, height: 800, webPreferences: { width: 0, height: 0, webPreferences: { nodeIntegration: true, // FIXME セキュリティ的に良くない }, }) mainWindow.loadFile(`${__dirname}/index.html`) // mainWindow.webContents.openDevTools() } const startMusic = () => { tray.setImage(ICON_PATH_PLAYING) if (mainWindow !== null) { mainWindow.webContents.send('play-bgm') } } const stopMusic = () => { tray.setImage(ICON_PATH_STOPPING) if (mainWindow !== null) { mainWindow.webContents.send('stop-bgm') } }
index.html
<DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>player</title> </head> <body> <script> const audio = new Audio('./audio/restaurant1.mp3') audio.loop = true const ipcRenderer = require('electron').ipcRenderer ipcRenderer.on('play-bgm', (event, args) => { audio.play() }) ipcRenderer.on('stop-bgm', (event, args) => { audio.pause() }) </script> </body> </html>
完成物
アプリ

メニュー
再生中のアイコン表示

まとめ
1から初めたが、調べながら数時間くらいでできた
全部入りみたいな感じで楽をしているせいもあるかもだが、これだけのアプリでも 179MB位になった。サイズが大きいのは少し気になる。(今回使ったmp3ファイルは 300KB くらいなので、mp3のせいではない)
とても簡単にできたので、ちょっとした機能が欲しいときに簡単なアプリを作ってみたりするのは面白そうだと思った
AWS Lambda に入門した
AWS Lambda に入門したので、やったことと理解したことのメモ
概要を読んだ
AWS Lambda(イベント発生時にコードを実行)| AWS
利点・仕組み・ユースケースを流し読みした。
価格と無料枠を確認した
料金 - AWS Lambda |AWS を読んだ。
AWS Lambda の無料利用枠には、1 か月ごとに 100 万件の無料リクエスト、および 40 万 GB-秒のコンピューティング時間が、それぞれ含まれます。
40 万 GB-秒のコンピューティング時間 って?と思ったが、例を読んだらすぐ分かった。
1GB(1024MB)のメモリを割り当てた場合に40万秒実行できるので、最低の128MBのメモリで実行した場合は
400000 秒 * 1024 MB / 128 MB = 3200000 秒 使える。
もし実行に10秒かかっても32万回。 軽めの処理で試す分には、気にしないで実行しまくって大丈夫そうだなと思った。
ただし以下 は注意が必要そうなので覚えておく。Provisioned Concurrency も後で確認する。
Lambda の無料利用枠は、Provisioned Concurrency が有効になっている関数には適用されません。
現在のところ、Lambda@Edge に無料利用枠はありません。
同じ AWS リージョン内における Amazon S3、Amazon Glacier、Amazon DynamoDB、Amazon SES、Amazon SQS、Amazon Kinesis、Amazon ECR、Amazon SNS、Amazon EFS、または Amazon SimpleDB と AWS Lambda 関数の間でのデータ転送は無料です。AWS Lambda 関数での VPC または VPC ピアリングの使用には、こちらで説明されている追加料金が発生します。
Hello World してみた
チュートリアルの サーバーレスコードを実行する方法 – アマゾン ウェブ サービス (AWS) を実施した
実行方法とテスト方法が分かった。
Black Beltの資料を読んだ
まずざっくり特性や注意点を把握するため Black Belt の AWS Lambda Part1 & Part2 を読んだ。
なお AWS クラウドサービス活用資料集 にはLambdaの資料が他にもたくさんあったので、一度触ってから再度読もうと思って飛ばした。
Part1 & Part2 を読んで
メモリ容量が一定を超えると使用するコア数も増えるため、マルチコアを活用するようなコードを実行することでより効率的な処理が可能
- 基本的にシンプルな処理で並列数を上げていくことで活用するものだと思ったが、メモリ容量が上がるとマルチコアになるらしい。
- でも
一定って?と思って調べたら、1.8GBらしいので、軽く触ってる分には気にしなくて良さそう。
Provisioned Concurrency
載ってなかったのは、資料日付の2019年4月にはまだ無くて、2019年の12月に発表された機能のため。
コールドスタート対策として、コンテナがウォームスタート状態になるようにしておく機能。 ただしLambda関数を実行しなくても、設定を有効化している間ずっとお金がかかる。リソース保持しておいてもらってるのでやっぱそうかという感じ。
コールドスタート対策として、CloudWatch Eventsで定期的にLambdaファンクションを起動する、といった対策方法があるらしいが、この機能で明示的に準備しておくことができるようになった。
前述の通り、無料利用枠も適用なし。
サーバーレスウェブアプリを構築した
他のサービスと組み合わせたチュートリアルとかか無いかな、と思ったらこれを発見したのでやっていく。
こんなwebアプリを作る。 ※上記サイトより引用
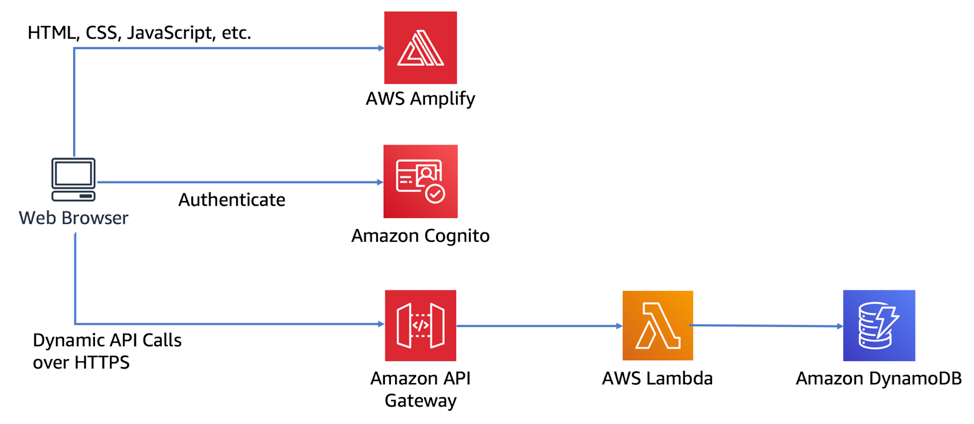
メモ
- モジュール 3: サーバーレスサービスバックエンド
[ランタイム] で [Node.js 6.10] を選択します。 - もう6.10は選べなかったので
Node.js 12.x最新を選択した。[Function code (関数のコード)] セクションまで下にスクロールし、index.js コードエディタの既存のコードを requestUnicorn.js の内容に置き換えます。 - 英語版はチュートリアルのページも移動していて、コードもここからダウンロードできた。 Lambda :: Wild Rydes Web Application
ページの右上にある [Save (保存)] をクリックします。 - 保存ではなく、デプロイ になっている。

- モジュール 5: リソースのクリーンアップ
感想
Amplify と Cognito
- 本筋と逸れるが、AmplifyとCognitoが強力だなーと思った。
- ただ裏でいろいろ勝手にやってくれるので、フルスタックフレームワーク感を感じた(覚えるの大変そう・作法だけ覚えれば使える・他に応用が効きにくそう)。 -良し悪しはまだ分からなかった。
API Gateway と Lambda
Lambda のコード
- Lambdaのコードは結局自分で書いていないが、使用した requestUnicorn.js はちゃんと読んでみた。
- Lambdaへのinput/outputはシンプルにするのが良さそうなので、あとは機能を調べながら書き足せしていけば良さそう。
- AWS Lambda とは - AWS Lambda や API リファレンス - AWS Lambda あたりは、流し読みしておいたほうがスムーズに書けそうだと思った。
Lambdaのコールドスタート
- 軽い処理ばかりだったせいなのか、概ねこういうものなのか分からないが、コールドスタートで何秒も待っているな、という気はあまりしなかった。
- Webページから同期呼び出し等でも問題ない感覚。
- もうちょっと実例を見たり、ログ等から見る方法を勉強してみたい。